When working on Spark jobs (in Scala), we often sequentially write the code in a single class, giving more attention to the transformations we do and forgetting how our code is structured or even if it’s tested.
Today I’ll be talking about how I personally like to structure and design my Spark jobs, such as they are highly maintainable and testable.
All the code is available in this GitHub Repository.
Example Spark job
The example Spark job that I’ll be using throughout the article is very simple:
- Loads 2 csv files: customers and transactions.
- Joins the two dataframes and performs aggregations:
- Items bought by customers and their last purchase date.
- How many times each item has been bought and its popularity (high or low).
object NormalJob extends Logging {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("SparkPageRank")
.getOrCreate()
// Load data
val customersDf = spark
.read
.option("header", "true")
.option("delimiter", ";")
.csv("C:/sample_data/customers.csv")
val transactionsDf = spark
.read
.option("header", "true")
.option("delimiter", ";")
.csv("C:/sample_data/transactions.csv")
.withColumn("items", split(col("items"), ","))
// Customer based aggregations
val customersAndTransactionsDf = customersDf.join(transactionsDf, Seq("userId"))
.drop("userId", "id", "joinDate")
val cbaDf = customersAndTransactionsDf.groupBy("name")
.agg(
flatten(collect_list("items")).as("allItemsBought"),
max("time").as("lastPurchaseTime")
)
// Item based aggregations
val itemsDf = transactionsDf.select("items")
.withColumn("item", explode(col("items")))
.drop("items")
var ibaDf = itemsDf.groupBy("item")
.agg(count("*").as("count"))
.orderBy(desc("count"))
ibaDf = ibaDf.withColumn("popularity",
when(col("count") >= 4, "high").otherwise("low"))
// Save results
cbaDf.coalesce(1).write.option("header", "true").parquet("C:/sample_data/cba")
ibaDf.coalesce(1).write.option("header", "true").parquet("C:/sample_data/iba")
}
}
This way of writing jobs introduces the following problems:
- Unless you move the code outside the main method, this is untestable.
- If you do move the code into its own class, what kind of tests will you do? Most likely, you’ll be testing the output of the job.
- A developer joining the team won’t be able to understand what the job does just from reading the test, because it doesn’t show what transformations are done to the data.
- Testing the output of a job is not granular enough. I wouldn’t even call it a unit test.
- If you’re refactoring the code, all you have to do is match the output at the end, which cannot handle all the possible cases your code might fall into, because we’ll tend to give it the right input data for it to succeed.
Let’s try and do better!
Redesigning the job
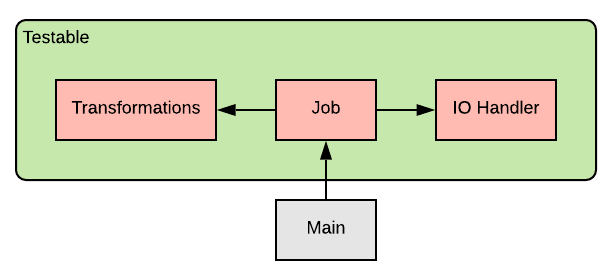
Redesigned job
To better understand this structure, let’s zoom at each component.
IO Handler
This class will handle everything related to IO, be it reading data from Hive or writing data to HDFS, it can do it all. Of course, you can create more specific classes depending on your needs.
This class is useful because:
- It’s an abstraction on top of
SparkSession, which is easier to test and mock. - It can contain some logic, for example: loading the last version of a dataset or setting common read/write options.
- In scenarios where you have multiple jobs (or sub jobs), IO operations are usually the same. This handler will remove a lot of duplicated code.
Let’s apply this to our old job:
class IOHandler(spark: SparkSession) {
def loadCsv(filename: String, header: Boolean = true, delimiter: String = ","): DataFrame = {
spark.read
.option("header", header)
.option("delimiter", delimiter)
.csv(filename)
}
def saveParquet(df: DataFrame, filename: String, header: Boolean = true): Unit = {
df.coalesce(1)
.write
.option("header", header)
.parquet(filename)
}
}
Transformations
This is an object (somewhat like a static class) that contains every transformation our job needs. The idea here is to put every transformation in it’s method so that we can test it alone.
This is a “static class” because I see transformations as pure functions, giving them the same input gives you the same result.
I personally split and use transformations in two ways:
val resultDf = Transformations.doSomething(...).val df = df.transform(Transformations.doSomething).- Thanks to Scala, the following will also work:
val df = df.transform(Transformations.doSomething(arg1, arg2))when the transformation needs outside arguments. Your method will need to be declared like this:doSomething(arg1, arg2)(df: DataFrame).
- Thanks to Scala, the following will also work:
Here are all the transformations extracted from the old job:
object Transformations {
/** Joins the two dataframes while dropping unnecessary columns */
def prepare(customersDf: DataFrame, transactionsDf: DataFrame): DataFrame = {
customersDf.join(transactionsDf, Seq("userId"))
.drop(col("id"))
}
/** Calculates, for each customer, the items he bought and the date of his last purchase.
*
* Returns: DataFrame[name string, allItemsBought array<string>, lastPurchaseTime string]
*/
def calculateCustomerBasedAggs(df: DataFrame): DataFrame = {
df.groupBy("name")
.agg(
flatten(collect_list("items")).as("allItemsBought"),
max("time").as("lastPurchaseTime")
)
.withColumn("allItemsBought", array_distinct(col("allItemsBought")))
}
/** Calculates, for each item, the number of times it was bought.
*
* Returns: DataFrame[item string, count int]
*/
def calculateItemBasedAggs(transactionsDf: DataFrame): DataFrame = {
val itemsDf = transactionsDf.select("items")
.withColumn("item", explode(col("items")))
.drop("items")
itemsDf.groupBy("item")
.agg(count("*").as("count"))
.orderBy(desc("count"))
}
/** Casts the "items" column into an array<string>. */
def castItemsToArray(transactionsDf: DataFrame): DataFrame = {
transactionsDf.withColumn("items", split(col("items"), ","))
}
/** Assigns the popularity of each item based on the number of times it was bought.<br />
* "high" if the item was bought 4 or more times, "low" otherwise.
*/
def assignPopularity(df: DataFrame): DataFrame = {
df.withColumn("popularity", when(col("count") >= 4, "high").otherwise("low"))
}
}
As you can see, each method does one specific thing. Even if transformations are related, they can still be split up. Obviously, your business rules will be the main driver here.
Job
This class is like an orchestrator, using the other components to serve a use case. It’s responsible for loading the data, transforming it then saving the results.
We are grouping everything in a separate class because it’s much easier to test.
class MaintainableJob(ioHandler: IOHandler) extends Logging {
def run(): Unit = {
// Load & prepare data
val customersDf = ioHandler.loadCsv("C:/sample_data/customers.csv", delimiter = ";")
val transactionsDf = ioHandler.loadCsv("C:/sample_data/transactions.csv", delimiter = ";")
.transform(Transformations.castItemsToArray)
val df = Transformations.prepare(customersDf, transactionsDf)
// Aggregations
val cbaDf = Transformations.calculateCustomerBasedAggs(df)
val ibaDf = Transformations.calculateItemBasedAggs(df).transform(Transformations.assignPopularity)
// Save results
ioHandler.saveParquet(cbaDf, "C:/sample_data/cba")
ioHandler.saveParquet(ibaDf, "C:/sample_data/iba")
}
}
Simple, clean and right to the point. You can further split the run method if it gets too long.
Main
I’m sure I don’t have to introduce you to the main class/method, what I will say though is this:
- Do not put logic or transformations here because it’s almost impossible to test this (I say almost because there are some workarounds that nobody really likes…).
- If your job requires arguments, then you might want to unit test that.
object Main {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Maintainable Job")
.getOrCreate()
val ioHandler = new IOHandler(spark)
val job = new MaintainableJob(ioHandler)
job.run()
spark.stop()
}
}
As you can see, the main method simply handles the SparkSession and runs our job.
Unit tests
Now to the fun (or not so much) part. This is where we build our confidence, where we become certain that our job will do exactly what we want it to do.
Here are the libraries I used in the tests:
- scalatest: The core testing library in Scala.
- mockito-scala: The popular mocking framework in Java, but in Scala!
- spark-fast-tests: A fast Spark testing helper.
We’ll be testing our testable components one by one:
IO Handler Tests
Since the IO Handler depends on the SparkSession, we only want to make sure it calls the right methods. Other test cases are already handled by Spark.
class IOHandlerTests extends WordSpec with MockitoSugar with Matchers with ArgumentMatchersSugar {
"loadCsv" should {
"call spark.read.csv with correct option values" in {
// Arrange
val spark = mock[SparkSession]
val mockReader = mock[DataFrameReader]
val ioHandler = new IOHandler(spark)
when(spark.read) thenReturn mockReader
when(mockReader.option("header", true)) thenReturn mockReader
when(mockReader.option("delimiter", ",")) thenReturn mockReader
// Act
ioHandler.loadCsv("filename")
// Assert
verify(mockReader).csv("filename")
}
}
"saveParquet" should {
"call write.parquet with correct options" in {
// Arrange
val spark = mock[SparkSession]
val mockWriter = mock[DataFrameWriter[Row]]
val mockDf = mock[DataFrame]
val ioHandler = new IOHandler(spark)
when(mockDf.coalesce(1)) thenReturn mockDf
when(mockDf.write) thenReturn mockWriter
when(mockWriter.option("header", true)) thenReturn mockWriter
// Act
ioHandler.saveParquet(mockDf, "filename")
// Assert
verify(mockWriter).parquet("filename")
}
}
}
Transformations Tests
These are the most important tests. Here, I’m only giving example tests, but you should be testing all the possible cases to ensure that each transformation works as expected.
Most of the tests will have the same structure:
- Create fake small dataframes using
toDF. - Execute the transformation and get an
actualDf. - Use the
assertSmallDatasetEqualitymethod to ensure the desired output.
class TransformationsTests extends WordSpec
with MockitoSugar
with Matchers
with ArgumentMatchersSugar
with SparkSessionTestWrapper
with DatasetComparer {
import spark.implicits._
"prepare" should {
"join the two dataframes and drop the id column" in {
// Arrange
val customersDf = Seq((0, "name")).toDF("userId", "name")
val transactionsDf = Seq((0, 0)).toDF("id", "userId")
val expectedDf = Seq((0, "name")).toDF("userId", "name")
// Act
val actualDf = Transformations.prepare(customersDf, transactionsDf)
// Assert
assertSmallDatasetEquality(actualDf, expectedDf)
}
"throw a NullPointerException when customersDf is null" in {
// Arrange
val customersDf = null
val transactionsDf = Seq((0, 0)).toDF("id", "userId")
// Act & Assert
assertThrows[NullPointerException] {
Transformations.prepare(customersDf, transactionsDf)
}
}
}
"calculateCustomerBasedAggs" should {
"aggregate by name" in {
// Arrange
val df = Seq(
("John", Array("a", "b"), "05/03/2020"),
("John", Array("c", "d"), "08/03/2020")
).toDF("name", "items", "time")
val expectedDf = Seq(("John", Array("a", "b", "c", "d"), "08/03/2020"))
.toDF("name", "allItemsBought", "lastPurchaseTime")
// Act
val actualDf = Transformations.calculateCustomerBasedAggs(df)
// Assert
assertSmallDatasetEquality(actualDf, expectedDf)
}
"remove duplicates in allItemsBought column" in {
// Arrange
val df = Seq(
("John", Array("a", "b"), "05/03/2020"),
("John", Array("b", "c", "d"), "08/03/2020")
).toDF("name", "items", "time")
val expectedDf = Seq(("John", Array("a", "b", "c", "d"), "08/03/2020"))
.toDF("name", "allItemsBought", "lastPurchaseTime")
// Act
val actualDf = Transformations.calculateCustomerBasedAggs(df)
// Assert
assertSmallDatasetEquality(actualDf, expectedDf)
}
}
"calculateItemBasedAggs" should {
"aggregate by item and calculate count per item (ordered by count)" in {
// Arrange
val transactionsDf = Seq((Array("a", "b", "c")), (Array("c", "d"))).toDF("items")
val expectedDf = Seq(("c", 2L), ("a", 1L), ("b", 1L), ("d", 1L)).toDF("item", "count")
// Act
val actualDf = Transformations.calculateItemBasedAggs(transactionsDf)
// Assert
assertSmallDatasetEquality(actualDf, expectedDf)
}
}
"castItemsToArray" should {
"cast items column into array<string>" in {
// Arrange
val transactionsDf = Seq("a, b, c").toDF("items")
// Act
val actualDf = Transformations.castItemsToArray(transactionsDf)
// Assert
assert(actualDf.schema.fields(0).dataType == DataTypes.createArrayType(DataTypes.StringType))
}
}
"assignPopularity" should {
"assign popularity correctly" in {
// Arrange
val df = Seq((2), (4), (5)).toDF("count")
val expectedDf = Seq((2, "low"), (4, "high"), (5, "high")).toDF("count", "popularity")
// Act
val actualDf = Transformations.assignPopularity(df)
// Assign
assertSmallDatasetEquality(actualDf, expectedDf, ignoreNullable = true)
}
}
}
Job Tests
Since our Job class acts like an orchestrator, we only have to make sure it calls the right methods with the right arguments. Everything else is already tested above.
class MaintainableJobTests extends WordSpec
with MockitoSugar
with Matchers
with ArgumentMatchersSugar
with SparkSessionTestWrapper
with DatasetComparer {
import spark.implicits._
"run" should {
"transform data and save results as parquet" in {
// Arrange
val customersDf = Seq(
(1, "Sam", "01/01/2020"),
(2, "Samantha", "02/01/2020")
).toDF("userId", "name", "joinDate")
val transactionsDf = Seq(
(1, 1, 20, "a,b,c", "01/01/2020"),
(2, 2, 10, "c,e,f", "02/01/2020"),
(3, 1, 39, "b,c,c,d", "03/01/2020")
).toDF("id", "userId", "total", "items", "time")
val cbaDf = Seq(
("Sam", Array("a", "b", "c", "d"), "03/01/2020"),
("Samantha", Array("c", "e", "f"), "02/01/2020")
).toDF("name", "allItemsBought", "lastPurchaseTime")
val ibaDf = Seq(
("c", 4L, "high"),
("b", 2L, "low"),
("a", 1L, "low"),
("e", 1L, "low"),
("f", 1L, "low"),
("d", 1L, "low")
).toDF("item", "count", "popularity")
val ioHandler = mock[IOHandler]
val cbaCaptor = ArgCaptor[DataFrame]
val ibaCaptor = ArgCaptor[DataFrame]
when(ioHandler.loadCsv("C:/sample_data/customers.csv", delimiter = ";")) thenReturn customersDf
when(ioHandler.loadCsv("C:/sample_data/transactions.csv", delimiter = ";")) thenReturn transactionsDf
// Act
new MaintainableJob(ioHandler).run()
// Assert
verify(ioHandler).saveParquet(cbaCaptor, eqTo("C:/sample_data/cba"), eqTo(true))
verify(ioHandler).saveParquet(ibaCaptor, eqTo("C:/sample_data/iba"), eqTo(true))
assertSmallDatasetEquality(cbaCaptor.value, cbaDf, ignoreNullable = true)
assertSmallDatasetEquality(ibaCaptor.value, ibaDf, ignoreNullable = true)
}
}
}
Multiple jobs
Having multiple jobs isn’t a sign of bad design, your jobs might share a common theme or use case, it’s quiet logical to put them in the same project.
The good thing is that you can still apply this approach! Here’s a demonstration:
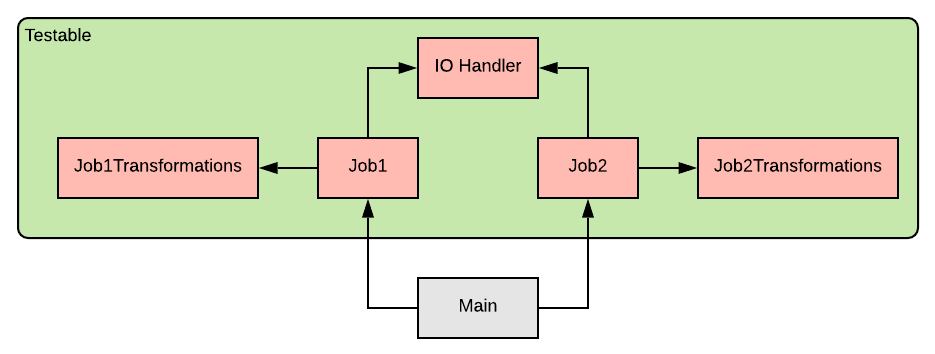
Multiple jobs design
As you can see, each job is separate, with its own transformations class, but they all share the same IOHandler. Everything can be tested separately.
A possible improvement is some kind of “main” job. It will be the one running all the jobs, and we can use it directly in Main. This will give us the ability to test that all the jobs are ran correctly, especially if we have outside arguments.
Conclusion
I’d like to remind the readers that this article is very opinionated. Many people agree (or will do, hopefully) with this approach, others won’t like it, and that’s completely fine.
As you can see, it doesn’t take a lot of effort to make a Spark job testable. The used example might not show the need enough, but imagine this with a bigger job/code base. Your Spark jobs (and you) can and should get the same goodness as all other software.
If there are other (better) approaches, please let me know and I’ll happily try them!
Happy coding!